Today we’re announcing a new feature: importing a CSV file to Relinx.
For this, we first select the “Import data” item from the menu next to our workspace.
Then select the CSV file containing data to be imported. Data is loaded and shown in the table. Check/uncheck the “Data has header” checkbox accordingly.
Import data from CSV file
Now we’re ready to define the mappings. We need to mandatorily select a column containing “Title”s of items and optionally a column containing “Note”s. If our file contains items of the same “Type” (e.g. Printers, Servers, etc), we map “Type” to an existing “Type” in the system. By the way, we can add a new “Type” from the autocomplete list without leaving the import page.
Columns not selected as “Title”, “Note” and “Type” can be imported as properties. For every column, we just need to select (or add) a corresponding “Property” or “Skip importing” this column altogether.
After mappings are defined click the “Import” button. A message should appear indicating successful import. If you experience any problems importing please contact support at [email protected]. If possible include the file too.
Warning: Currently imported items are not merged with existing items so you can import the data to a test workspace before final import to production.
Businesses today use lots of different tools to have work done, and these tools should have some ways of integrating. Relinx is no different. While managing your data in a web app can be comfortable at some level, there’re lots of data to be organized that are already available outside.
To enable better integration with your existing tools, we have published REST API access to the Relinx. And we made API Access feature free available even for free-tier users. Rich documentation and Postman collection/environment are available at https://github.com/relinx-io/api-docs.
Today we announce some cool new features added to Relinx. Let’s describe them a bit.
Tiers
We’ve added two tiers (plans): PRO and VIP. All functionality available until now is still available in the Free tier. Some features like Workspaces and Sharing are available only to PRO/VIP members. Higher tiers also have higher storage/size limits. PRO/VIP plans are free for the moment. You can experiment with them without any charge.
Workspaces
PRO/VIP users can now have multiple workspaces to better organize their data. In the future, we’re planning to add sharing data between workspaces. Stay tuned.
Sharing
Every workspace can be independently shared with other team members. Readonly or read/write access can be granted to a member. In the future, fine-tuned security rules will be added for VIP members.
What is next?
We’re working on REST API access to the app. At first, we wanted to make it a PRO feature. But because Relinx is free for individual use, they have should be able to use that feature too.
Meanwhile, upvote for upcoming features and feel free to drop us your thoughts at [email protected]
Applications, even databases come and go, but data is the most important part of the story. Usually, data is the purpose of the system exists in the first place. That’s why we should consider a database system not only as a black box to hold our data, but also a tool to verify and guard it against corruptions.
This is achieved with a help of robust and well-thought database design. Of course, business logic is coded in the application layer and it makes sure data is in a proper format before arriving at the database. But who guarantees that a network failure or a bug will not allow corrupted “guests”? Also, the application layer is not the only “door” to the database. We can have import scripts, maintenance scripts, and mere mortal DBAs and developers interacting with it. Having preventive measures at a very low level ensures our data is always checked before stored.
Having robust, reliable data also helps with development and testing. Setting a column as a Not Null excludes many test scenarios assuming the emptiness of that column and also simplifies code freeing developers to check value [nearly] every time before accessing it.
Having stressed the importance of good database design, let’s have a look at the tools at our disposal to achieve it.
Normalization
This is of no doubt the first rule of good design. We are not going to delve into normalization rules here, just want to emphasize it’s importance. A good piece of reading about the topic could be this article.
Data Types
Defining proper types for attributes is another thing that needs attention. This will not only improve the performance of the database but also validate the data before storing it. So we should keep numeric data in “integer”, “numeric” fields. Timestamps in “timestamp”, “timestamptz” fields. Booleans in “bit”, “char(1)” or “boolean” (whichever RDBMS supports) fields, etc.
Dates deserve a specific mention. If a Date attribute is supposed to have only the date part (OrderDate, ReleaseDate) use a type without a time portion (“date”). If you need to keep only the time (StartTime, EndTime) use a suitable time type. If you don’t need precision specify it as zero (“time(0)”). The problem with dates having a time portion is that you always have to cut off the time part to display only the date and make sure not to display yesterday or tomorrow when you format it in a different timezone than your database. Dates with time portion also may cause problems with subtracting and addition when hopping over daylight change dates.
Constraints are our main topic of discussion today. They are what keeps invalid data out and ensures the robustness of it. Let’s look at them one by one.
Not Null Constraint
If business rules state that attribute should always be present, make it Not Null without hesitating. Good candidates to be Not Null are fields like Id, Name, AddedDate, IsActive, State, CategoryId (if all items should have a category), ItemCount, Price, and many others. Usually, these attributes play important roles in business logic. Other optional informative fields may still be Null.
But be careful not overusing Not Null constraint for attributes that CAN BE Null. For example, a long-running Task always has a StartTimestamp (Not Null), but EndTimestamp is updated only when the task finishes (Null). Or another classic example: Employee table has ManagerId, but not all employees have a manager. Don’t be tempted to make ManagerId Not Null and insert “0” or “-1” for employees that don’t have a manager. This will lead to other problems down the way when we will be adding Foreign Key constraints.
Unique Constraint
Again, depending on business rules, some attributes (or combinations of attributes) should be unique, such as Id, PinNumber, BookId and AuthorId, OrderNo, etc. These attributes should be made unique by adding Unique constraints. One more note: you may use Unique Index to achieve the same effect, but adding constraint is a better approach. Because when you add a Unique constraint a non-unique index is created automatically. So if for some reason you would have to temporarily disable/enable the constraint it’d be very easy. In the case of a unique index, you would have to drop/recreate the index which is an expensive operation in terms of performance degradation and time.
Primary Key
Not Null and Unique constraints together make up a Primary Key. Columns like Id or ObjectId quickly come to mind when we think of primary keys. But primary keys can also be composite, like BookId and AuthorId. The dilemma here is whether to have a separate Id column as a primary key, or make a composite primary key of them both? Having a separate Id column is usually a better method as it makes your joins cleaner and also allows easily add another column to a unique combination. However, having a separate primary key (Id) doesn’t free us from the need to add a Unique constraint to BookId and AuthorId columns.
Check Constraint
Check constraints allow us to define valid values/ranges for data. Perfect candidates for check constraints are Percent (between 0 and 100), State (0, 1, 2), Price, Amount, Total (greater than or equal to 0), PinNumber (fixed length), etc. Again don’t try to code business logic into check constraints. I remember a case when adding a Check constraint “greater than or equal to zero” to the AccountBalance column saved us from accidental over-drawing balances.
Default Constraint
Default constraints are also important. They allow us to add new Not Null columns to existing tables and make the “older” API to be compatible with the new structure until all parties are upgraded (though after complete upgrade default constraint should be removed).
One thing to remember here. Don’t code business logic into a Default constraint. For example function “now()” can be a good fit (though not always) as a default value for a Timestamp field in a Log table, but not for an OrderDate field in an Orders table. You may be tempted to omit OrderDate in inserts, relying on a default constraint and this means spreading your business logic down to the database level. Also at some point business may decide to assign OrderDate only after it has been approved and because the Default constraint is buried deep into the database it will not be obvious when we make changes to the code in the application layer.
Foreign Key Constraint
Foreign Key constraints are the keys of relational database design. Together with Primary Keys, Foreign Keys ensure data consistency at the inter-table level. Normalization rules tell us when to extract data into its table and reference it with Foreign keys. Here we will focus on subtle nuances, like OnDelete and OnUpdate rules.
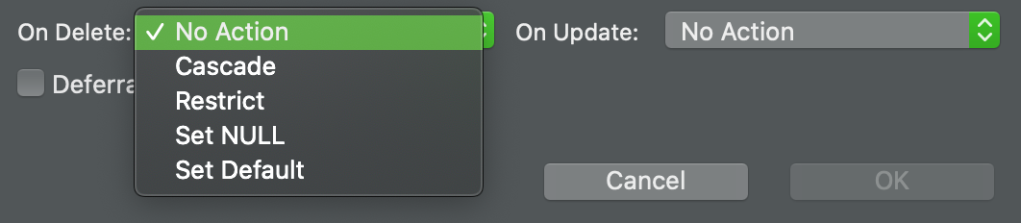
Foreign Key editor dialog in DBeaver
Let’s start with the easy part: OnUpdate. Foreign keys reference primary keys and they are rarely (if ever) changed. So the OnUpdate rule is not very popular, but it makes sense to set it to Cascade, as sometimes we may have to update the primary keys of some rows (usually after migration). This way database will allow us to make the update and new ids will be propagated to the child tables.
OnDelete rule is a bit more complicated. Depending on the database we have options NoAction, Restrict, SetNull, SetDefault, and Cascade. So which one to choose?
NoAction is usually selected for keys referencing lookups or entities that can exist without referencing entity. For example, Products -> Categories, Books -> Authors, etc. Restrict in most cases is the same as NoAction, though for some databases there’re subtle differences.
On the other hand, Cascade is selected when child records can not exist without their parent. In Book and Author example, when a book is removed we should remove records from the BookAuthor table too. Other examples: OrderDetails -> Orders, PostComments -> Posts etc. Here some of you may disagree that the database should not automatically remove child rows, they should be removed by the application layer. Depending on business logic, yes, that’s true. But sometimes “unimportant” child deletions can be delegated to the database.
SetNull is rarely used. For example, the Foreign key between Employee.ManagerId and Employee.Id can be Set Null. When a manager is removed (if ever) his subordinates become orphans. Obviously, this rule should be selected only if the column is nullable.
SetDefault is the rarest among his counterparts. It sets the column to its default value when the parent record is removed. Because foreign keys reference primary keys we can hardly imagine a hard-coded default value for a field with a foreign key. But anyway this option exists in case we need it.
Indexes
Indexes are an important part of good database design, but a bit off-topic for our discussion, as they do little to protect our data (except for unique indexes).
Conclusion
A well-thought design can save us many hours of coding, testing, and troubleshooting. Writing queries and reports against a well-designed database is a pleasure. Publishing and migrating that data to a new system is also very easy.
Opinions presented in this article are the result of many years dealing with various database systems. Some may be suitable for your case and some even contrary. So don’t take them for granted.
We have been busy adding a high-demanded feature to the Relinx these days: History of changes. No matter whether we are using Relinx as a CMDB (Configuration Management Database), IT Asset management tool or to keep track of Client requirements we need to know it’s history: who and when made changes to the data.
When we will soon add multi-user functionality to Relinx the importance of keeping the history of changes will even increase. Employees will be more responsible for the changes they made when they see that tracks are visible throughout the organization.
Keeping history is also a major requirement for international standards like ISO 9001, ITIL, or CMM (Capability Maturity Model).
Our way of keeping history is such that changes show up not only in the place of change but also in related entities too. For example, when you add a link between items A and B it will show up in the log of both items. And when you change that link from A to C it will be shown in the history of A as an Update Link, in history of B as a Delete Link and in history of C as an Insert Link. We also added the “History” menu to browse and search all history records.
Our next planned feature is adding data types to the Properties. We’re planning to do it Relinx way: simple, flexible but powerful 🙂
P.S. We also added a read-only demo account to taste the system without registering. Head to https://app.relinx.io/login and login with demo credentials written on the login page.
Today we announce the first release of Relinx. It has been a while since we started working on it. Our goal is to make it free for personal use and add premium features for teamwork later.
The main difference between Relinx and other similar tools in its flexible design. Other tools let you define powerful data models but changing them later is very hard if not impossible. Your data is bound to the model and changing the model leads to changes in data. Here, in contrast, model acts only as a reference, you’re free to change it and your data remains intact, but the system shows you inconsistencies between the model and data.
So, the journey begins. We’ll keep adding new features and share them in our blog. See you in the next release! Stay tuned!